1. Confluent简介
1.1 Confluent 背景
LinkedIn的Kafka研发团队,有个三人小组出来创业了。基于这项技术Jay Kreps带头创立了新公司Confluent,Confluent的产品围绕着Kafka做的。 Confluent 致力于为各行各业的公司提供实时数据处理服务的解决方案。该公司已获 LinkedIn 等公司的融资。
1.2 Confluent 定位
Kreps将Kafka描述为LinkedIn的“中枢神经系统”,管理从各个应用程序汇聚到此的信息流,这些数据经过处理后再被分发到各处。
不同于传统的企业信息列队系统,Kafka是以近乎实时的方式处理流经一个公司的所有数据,目前已经为LinkedIn, Netflix, Uber和Verizon建立了实时信息处理平台。
因此,Confluent Platform 是一个流数据平台,能够组织管理来自不同数据源的数据,拥有稳定高效的系统。
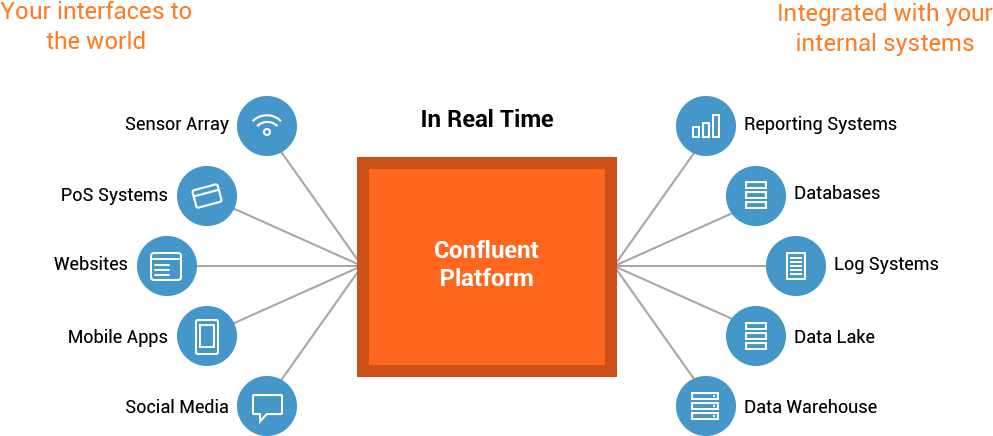
流式数据处理平台不仅提供了应用系统传输数据的能力,又提供了连接数据源,应用系统,数据管道等所需的全部工具。
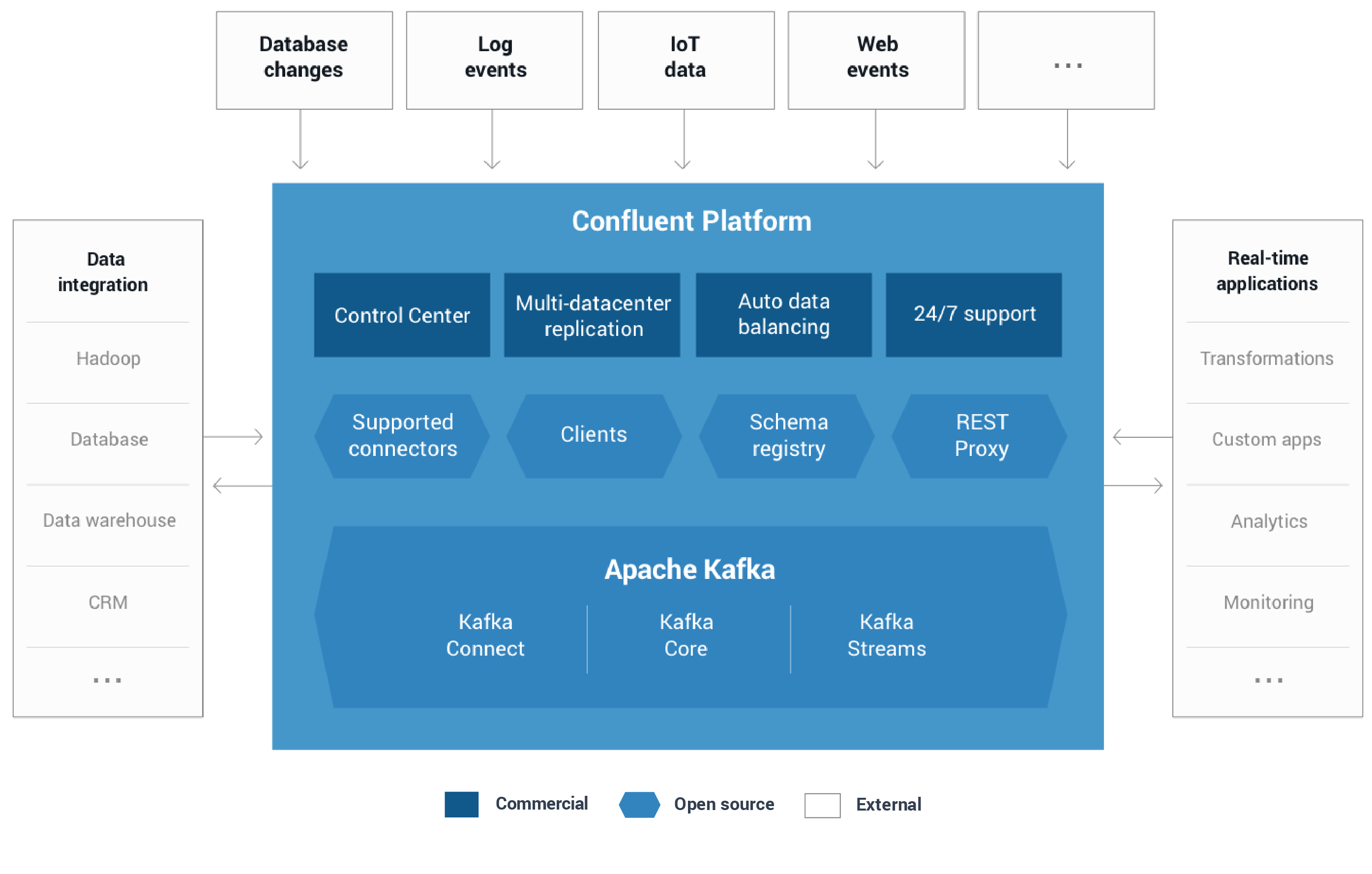
Confluent Platform 可以低成本建立实时数据管道和流应用。通过将多个来源和位置的数据集成到一个中央数据流平台,Confluent Platform使您可以专注于如何从数据中获得商业价值而不是担心底层机制,如数据是如何传输或不同系统间的风险,异常。具体来说,Confluent Platform简化了连接数据源到Kafka,用Kafka构建应用程序,以及安全,监控和管理您的Kafka的基础设施。
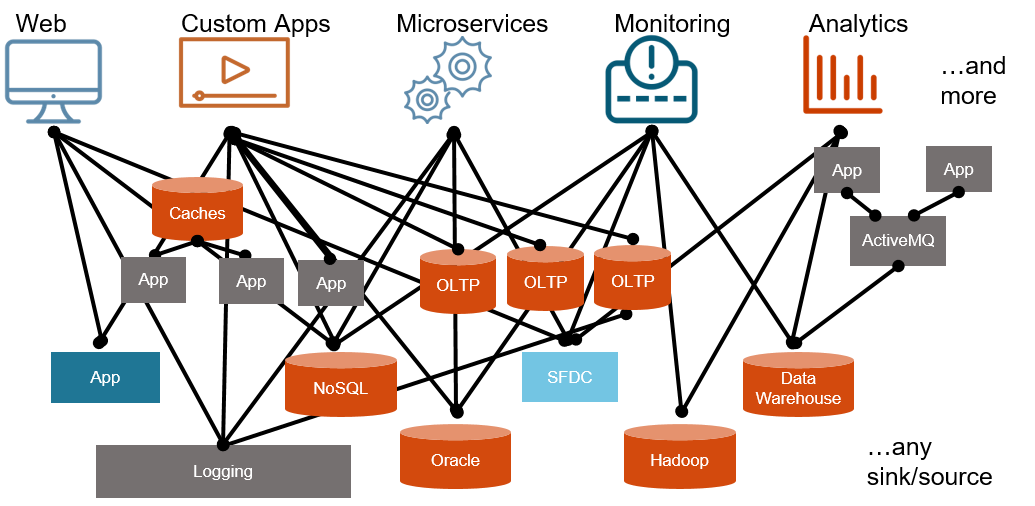
传统架构模式:
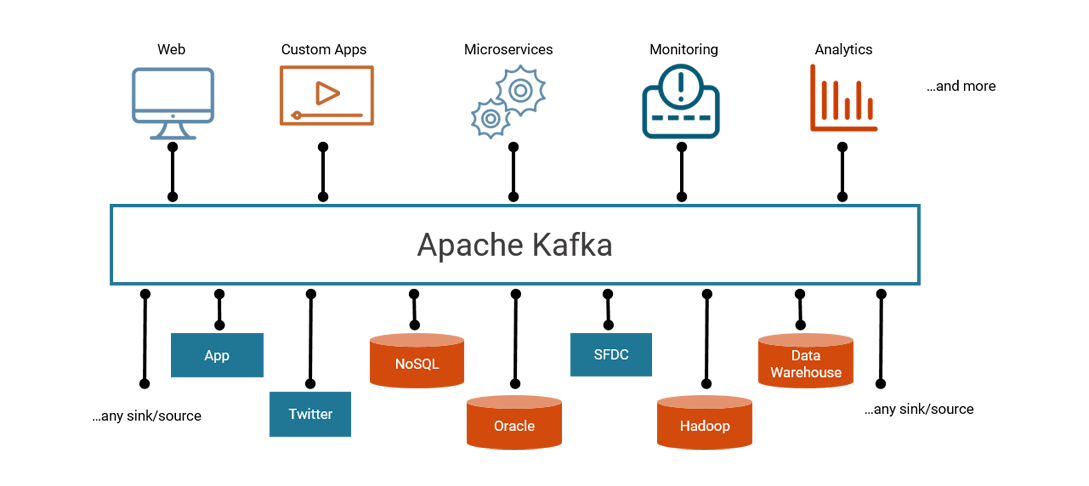
Kafka–分布式流数据平台:
Confluent Platform–在Kafka基础上,更加完善的分布式数据流平台:
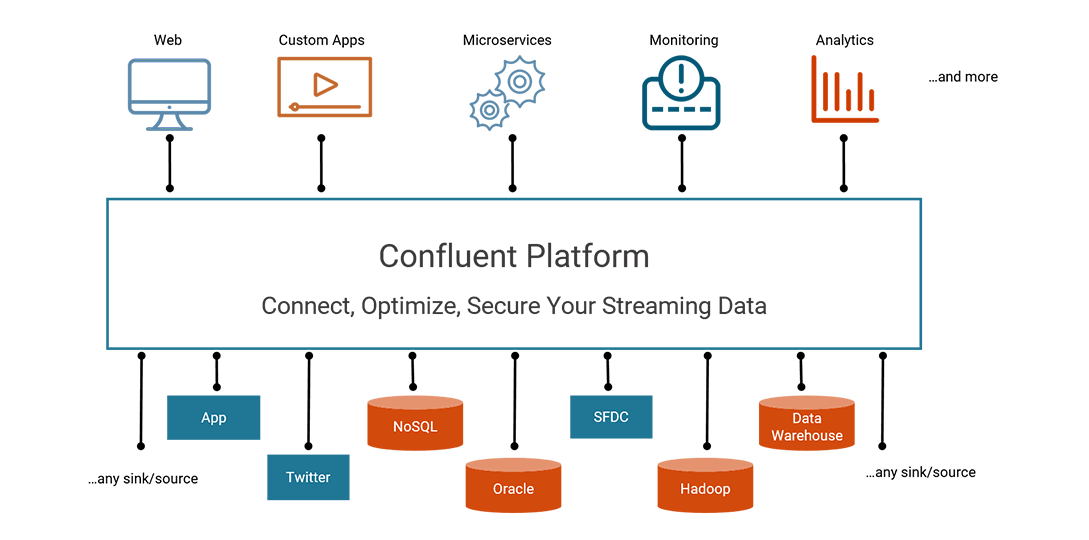
Confluent Platform:
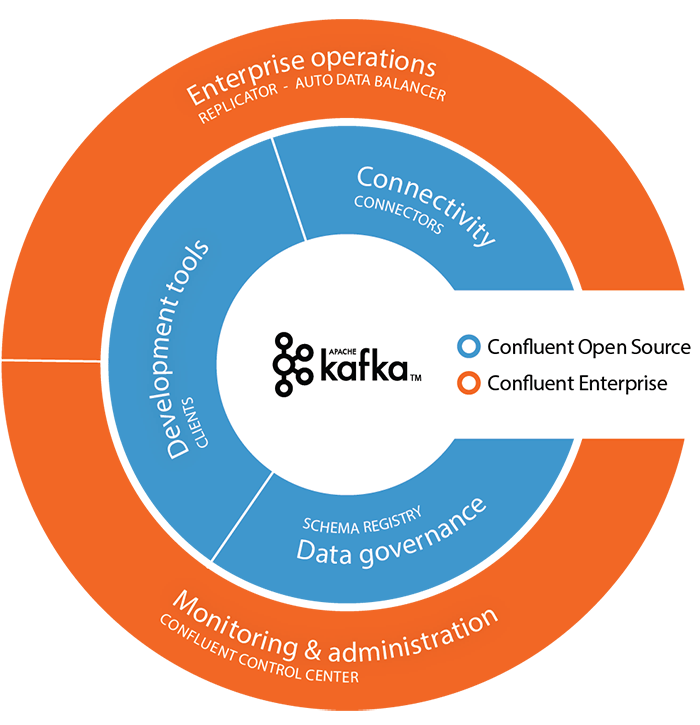
总的来说,Confluent Platform平台的组件致力于通过统一而灵活的方式建立一个企业范围的数据流平台。
1.3 Confluent 组件
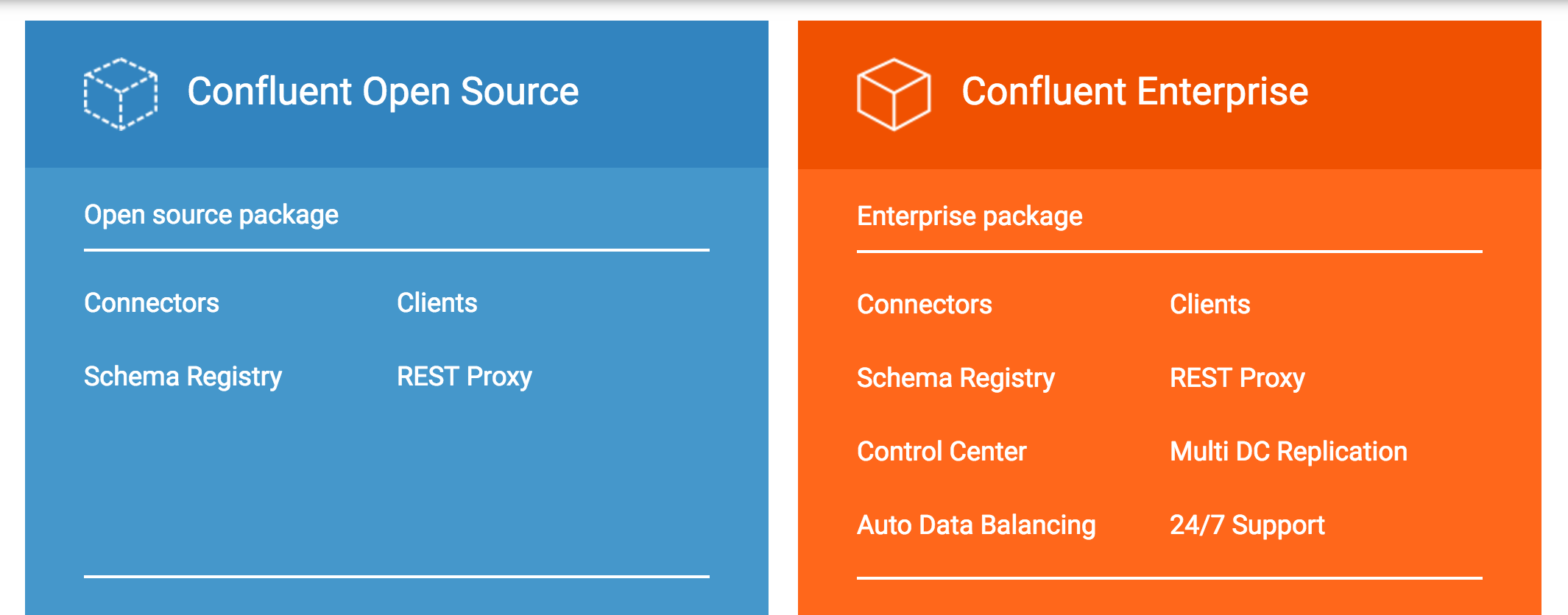
Kafka组件:
- Kafka Java Clients(开源)。 Kafka Clients Java 库,向 kafka 写消息或者从 kafka 读消息。
- Kafka Streams(开源)。 Kafka Streams是一个流式数据处理库,使kafka成为功能齐全的流处理系统。
- Kafka Connect(开源)。 一种可扩展的和可靠的连接Kafka框架与外部系统(如数据库,键值存储,搜索索引和文件系统)的框架。
除了Kafka以外, Confluent Platform 包括更多的工具和服务,使构建和管理数据流平台更加容易。
Confluent Platform开源组件:
- Confluent Kafka Connectors(开源)。Kafka Connectors 中的 Kafka Connector API使得Kafka可与其他数据系统相连接,如Hadoop等。 Confluent 再次基础上完善了更多的connectors,包含当前大多数主流的数据源和数据接收器系统。
- Confluent Kafka Clients(开源)。其他编程语言的 Kafka Clients 库,包括C/C++,Python,Go,.Net等。
- Confluent Schema Registry(开源)。Schema 注册服务。确保每一个应用系统使用正确的schema写入数据,确保发送到同一topic的消息格式一致,保证兼容性。
- Confluent Kafka REST Proxy(开源)。应用系统通过RESTful HTTP服务,和kafka之间发送和接收消息。
Confluent Platform闭源组件:
- Automatic Data Balancing(闭源)。数据自动负载均衡。
- Multi-Datacenter Replication(闭源)。多数据中心备份。
- Confluent Control Center(闭源)。最全面的管理和监控Kafka的GUI系统。
- JMS Client(闭源)。Kafka JMS 兼容组件。
2. Confluent使用
2.1 Confluent 下载
下载地址:https://www.confluent.io/download/
2.2 Confluent 启动
要求
JAVA >= 1.7
组件配置
默认配置:
| Component | Default Port |
|---|---|
| Zookeeper | 2181 |
| Apache Kafka brokers (plain text) | 9092 |
| Schema Registry REST API | 8081 |
| REST Proxy | 8082 |
| Kafka Connect REST API | 8083 |
| Confluent Control Center | 9021 |
启动
1 | confluent start schema-registry |
可以看到输出如下的日志:1
2
3
4
5
6Starting zookeeper
zookeeper is [UP]
Starting kafka
kafka is [UP]
Starting schema-registry
schema-registry is [UP]
也可单独启动每一个进程:1
2
3$ ./bin/zookeeper-server-start ./etc/kafka/zookeeper.properties
$ ./bin/kafka-server-start ./etc/kafka/server.properties
$ ./bin/schema-registry-start ./etc/schema-registry/schema-registry.properties
2.3 Confluent Producer
1 | ./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic test --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}' |
再持续输入待发送的消息1
2
3{"f1": "value1"}
{"f1": "value2"}
{"f1": "value3"}
2.4 Confluent Consumer
1 | ./bin/kafka-avro-console-consumer --topic test --zookeeper localhost:2181 --from-beginning |
2.5 错误schema
1 | ./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic test --property value.schema='{"type":"int"}' |
会出现如下的错误:1
2
3
4
5
6
7
8
9
10org.apache.kafka.common.errors.SerializationException: Error registering Avro schema: "int"
Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Schema being registered is incompatible with the latest schema; error code: 409
at io.confluent.kafka.schemaregistry.client.rest.utils.RestUtils.httpRequest(RestUtils.java:146)
at io.confluent.kafka.schemaregistry.client.rest.utils.RestUtils.registerSchema(RestUtils.java:174)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.registerAndGetId(CachedSchemaRegistryClient.java:51)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.register(CachedSchemaRegistryClient.java:89)
at io.confluent.kafka.serializers.AbstractKafkaAvroSerializer.serializeImpl(AbstractKafkaAvroSerializer.java:49)
at io.confluent.kafka.formatter.AvroMessageReader.readMessage(AvroMessageReader.java:155)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:94)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
3. KSQL 简介
KSQL 是 Kafka 的一个流式处理引擎。提供了对 Kafka 流处理一个简单的和完全交互式 SQL 接口;无需在使用 java 或 python 编写代码。KSQL 是开源的(Apache 2.0 licensed)、分布式、可扩展的、可靠的、实时的。它支持一系列强大的流处理的操作包括聚合,连接,窗口,会话化,以及其他更多功能。
4. KSQL 编译&启动
4.1 要求
- KSQL 目前是研发人员预览版,不要在生产环境使用
- Confluent Platform 3.3.0
- MAVEN
- GIT
- JAVA >= 1.8
4.2 编译
clone
1 | $ git clone git@github.com:confluentinc/ksql.git |
install
1 | $ cd ksql |
4.3 启动
1 | $ ./bin/ksql-cli local |
成功会如下:
1 | ====================================== |
5. KSQL 生产消息
使用 KSQL 提供的 examples 程序,每隔10s,持续地向 pageviews topic 发送一条消息,消息格式为 DELIMITED 格式。
1 | $ java -jar ksql-examples/target/ksql-examples-0.1-SNAPSHOT-standalone.jar quickstart=pageviews format=delimited topic=pageviews maxInterval=10000 |
使用 KSQL 提供的 examples 程序,每隔10s,持续地向 users topic 发送一条消息,消息格式为 JSON 格式。
1 | $ java -jar ksql-examples/target/ksql-examples-0.1-SNAPSHOT-standalone.jar quickstart=users format=json topic=users maxInterval=10000 |
6. KSQL 查询
6.1 创建 STREAM 和 TABLE
STREAM
通过 Kafka topic pageviews,创建一个 STREAM,指定 value_format 格式为 DELIMITED 格式。
1 | ksql> CREATE STREAM pageviews_original (viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='DELIMITED'); |
使用 DESCRIBE 命令,查询刚刚新建的 STREAM。可以看到 KSQL 添加了额外的列,列名为 ROWTIME,相当于 Kafka 消息的时间戳;和额外的列,列名为 ROWKEY,相当于 Kafka 消息的key。
1 | ksql> DESCRIBE pageviews_original; |
TABLE
通过 Kafka topic users,创建一个 TABLE,指定 users_original 格式为 JSON 格式。
1 | ksql> CREATE TABLE users_original (registertime bigint, gender varchar, regionid varchar, userid varchar) WITH (kafka_topic='users', value_format='JSON'); |
使用 DESCRIBE 命令,查询刚刚新建的 TABLE。
1 | ksql> DESCRIBE users_original; |
SHOW
展示全部 STREAMS 和 TABLES
1 | ksql> SHOW STREAMS; |
6.2 查询语句
SELECT
使用 SELECT 语句创建一个 query ,并从 STREAM 中返回数据。
1 | ksql> SELECT pageid FROM pageviews_original LIMIT 3; |
持久化查询
在SELECT语句之前,使用 CREATE STREAM 关键字来创建持久化查询。与刚刚的非持久性的查询相比,持久化查询的结果会写入到一个 Kafka 的 PAGEVIEWS_FEMALE topic中去。如下的查询语句,通过和 users_original TABLE的 userid字段上做 LEFT JOIN操作,使得结果是在 pageviews STREAM 基础上,更加丰富的一种表现。
1 | ksql> CREATE STREAM pageviews_female AS SELECT users_original.userid AS userid, pageid, regionid, gender FROM pageviews_original LEFT JOIN users_original ON pageviews_original.userid = users_original.userid WHERE gender = 'FEMALE'; |
SELECT 查询持久化查询语句的结果
1 | ksql> SELECT * FROM pageviews_female; |
LIKE 关键字&指定topic
创建新的持久化查询语句,使用 LIKE 关键字。且指定了输出 topic ,该持久化查询语句的结果会写入 Kafka 的 pageviews_enriched_r8_r9 topic中。
1 | ksql> CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9', value_format='DELIMITED') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9'; |
滚动时间窗口&统计
创建持久化查询语句,对 pageviews_female STREAM, 在30s的滚动时间窗口内,进行计数。结果会写入到 PAGEVIEWS_REGIONS topic 中。
1 | ksql> CREATE TABLE pageviews_regions AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_female WINDOW TUMBLING (size 30 second) GROUP BY gender, regionid HAVING COUNT(*) > 1; |
查询1
2
3
4
5
6
7
8ksql> SELECT regionid, numusers FROM pageviews_regions LIMIT 5;
Region_3 | 2
Region_7 | 2
Region_4 | 2
Region_4 | 2
Region_4 | 3
LIMIT reached for the partition.
Query terminated
查看全部持久化查询语句
1 | ksql> SHOW QUERIES; |
7. KSQL 架构
単例模式: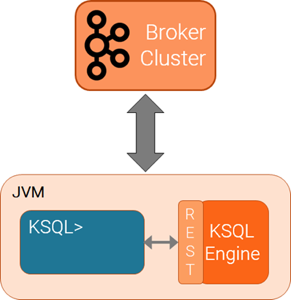
Client-server模式: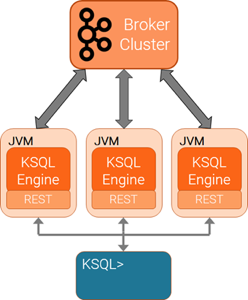
特点:
- KSQL CLI 是 client 端,是一个控制台。
- KSQL Engine 是 server 端,负责计算执行。
- client 与 server 通过 http 连接。
- Client-server 集群模式中,所有的 servers 共享用户提交的 KSQL 查询语句的计算任务。
- 支持水平扩展。可动态添加 KSQL server 实例,以提升整体集群的容量和计算能力。
- 可动态减少 KSQL server 实例,以降低整体集群的容量和计算能力。其余的 KSQL servers 会对集群全部的查询计算任务自动负载均衡。